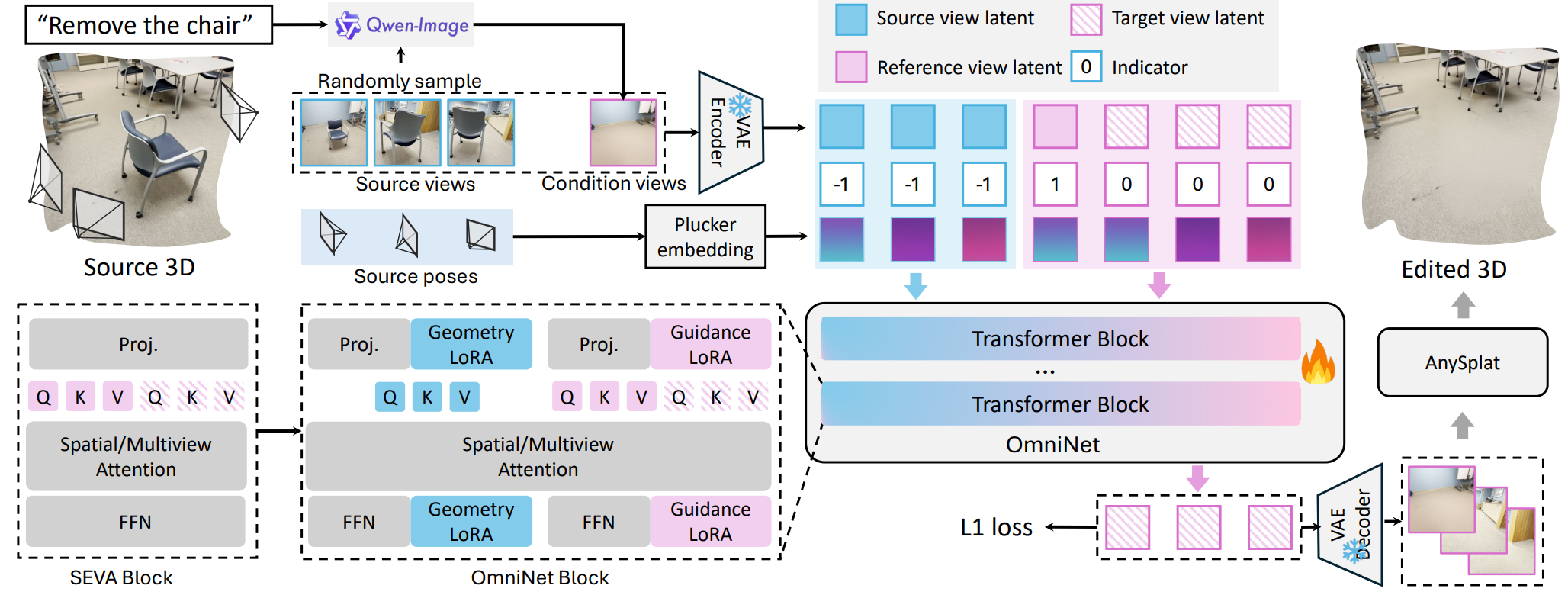
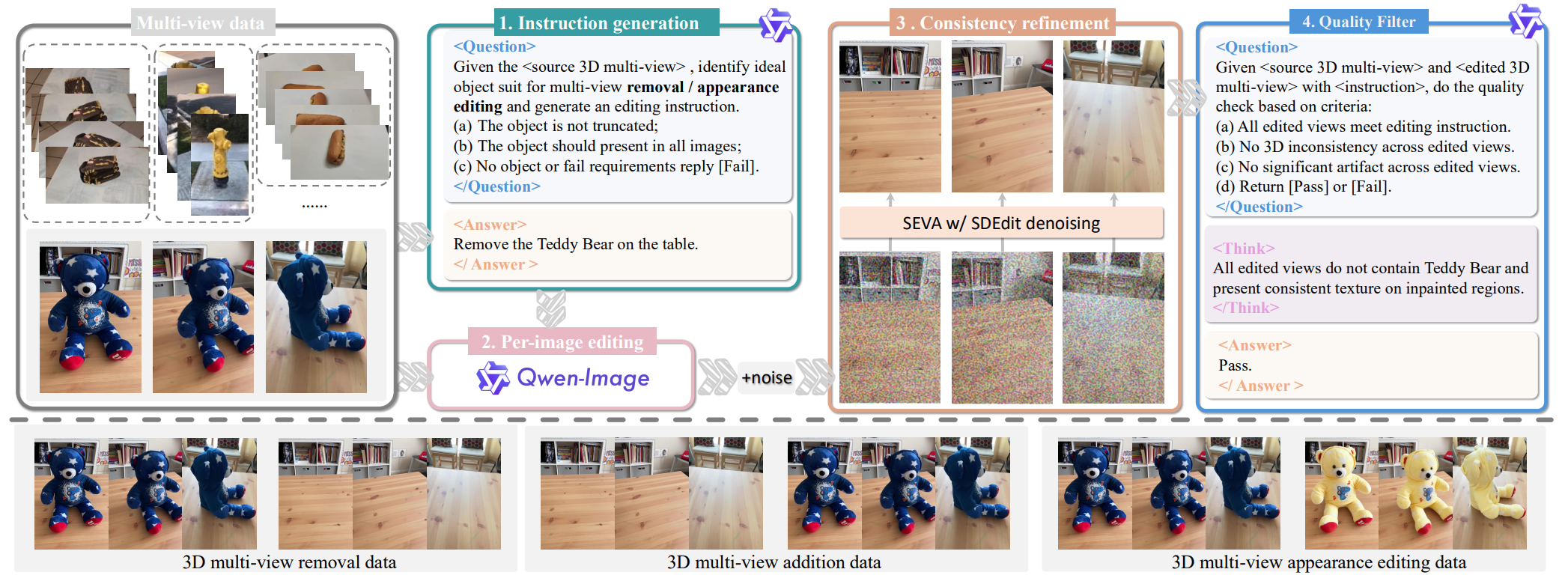
Most instruction-driven 3D editing methods rely on 2D models to guide the explicit and iterative optimization of 3D representations. This paradigm, however, suffers from two primary drawbacks. First, it lacks a universal design of different 3D editing tasks because the explicit manipulation of 3D geometry necessitates task-dependent rules, e.g., 3D appearance editing demands inherent source 3D geometry, while 3D removal alters source geometry. Second, the iterative optimization process is highly time-consuming, often requiring thousands of invocations of 2D/3D updating. We present Omni-3DEdit, a unified, learning-based model that generalizes various 3D editing tasks implicitly. One key challenge to achieve our goal is the scarcity of paired source-edited multi-view assets for training. To address this issue, we construct a data pipeline, synthesizing a relatively rich number of high-quality paired multi-view editing samples. Subsequently, we adapt the pre-trained generative model SEVA as our backbone by concatenating source view latents along with conditional tokens in sequence space. A dual-stream LoRA module is proposed to disentangle different view cues, largely enhancing our model's representational learning capability. As a learning-based model, our model is free of the time-consuming online optimization, and it can complete various 3D editing tasks in one forward pass, reducing the inference time from tens of minutes to approximately two minutes. Extensive experiments demonstrate the effectiveness and efficiency of Omni-3DEdit.